Việt Nam xây dựng thành công phần mềm dịch ngôn ngữ hiếm khu vực Đông Nam Á
Trong đó, Viện đã xây dựng được hệ thống dịch văn bản đa ngữ giữa tiếng Việt với các ngôn ngữ của khu vực bao gồm tiếng Lào, tiếng Khmer, tiếng Thái Lan, tiếng Malaysia và tiếng Indonesia.
Dịch máy tự động là một trong những ứng dụng thành công nhất của lĩnh vực xử lý ngôn ngữ tự nhiên. Các hệ thống dịch máy chất lượng cao như Google Translate của Google, Bing Translator của Microsoft… cần các bộ dữ liệu song ngữ quy mô lớn, lên tới hàng triệu cặp câu để huấn luyện mô hình. Tuy nhiên, rất nhiều ngôn ngữ trên thế giới không có đủ tài nguyên như vậy.
Mặt khác, Google Translate hay Bing Translator có chất lượng dịch rất tốt cho các câu đơn. Việc dịch một đoạn văn bản dài hơn, có tham chiếu thực thể, ngữ cảnh giữa các câu làm ảnh hưởng tới chất lượng dịch, khiến nhiều câu dịch có phần ngô nghê. Bên cạnh đó, các hệ thống này không có chất lượng dịch tốt đồng đều cho tất cả các cặp ngôn ngữ, đặc biệt là các ngôn ngữ nghèo tài nguyên như tiếng dân tộc thiểu số của Việt Nam hoặc các ngôn ngữ hiếm như tiếng Lào, Khmer…
Một vấn đề nữa của các hệ thống nói trên là khả năng thích ứng miền chuyên biệt (domain-specific). Nghĩa là, chúng có thể dịch tốt cho miền ngôn ngữ chung, phổ thông phục vụ đại chúng (general public) nhưng chất lượng dịch rất kém trong các miền ngôn ngữ mang tính chuyên môn như y tế, luật pháp, an ninh…
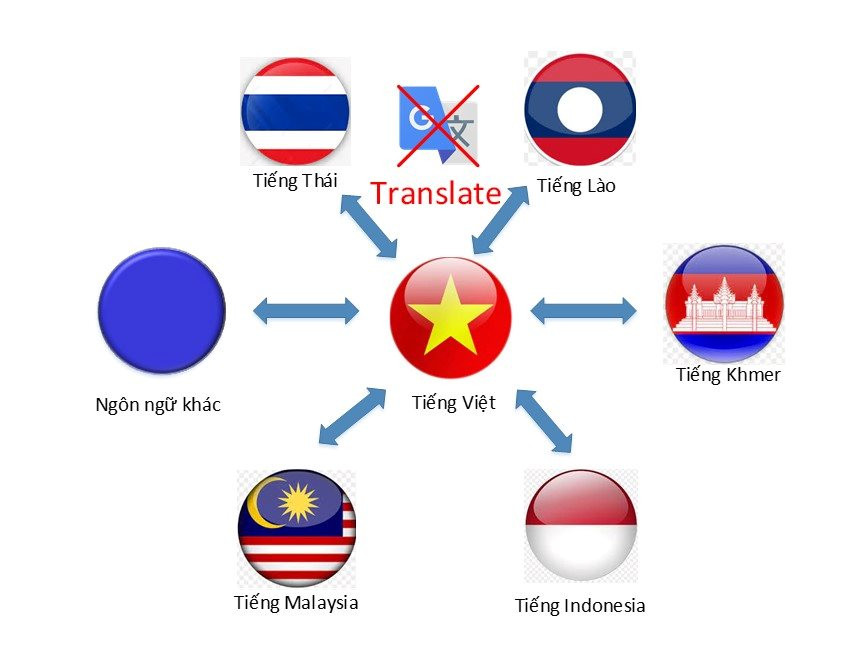
Để khắc phục các tồn tại nói trên, nhóm nghiên cứu tại Viện Công nghệ thông tin do Tiến sĩ Nguyễn Việt Anh làm chủ nhiệm đã phát triển một hệ thống dịch thuật lấy tiếng Việt làm trung tâm, có khả năng dịch hai chiều sang các ngôn ngữ nghèo tài nguyên với chất lượng tốt. Phần mềm này có chất lượng luôn tương đương hoặc cao hơn Google Translate đối với cùng văn bản. Ngoài ra, phần mềm không hạn chế độ dài của văn bản.
Trong giai đoạn 2022-2023, để tập trung vào một số hợp đồng với đối tác nước ngoài, hệ thống tập trung vào triển khai kỹ thuật mô hình ngôn ngữ lớn (Large Language Models - LLMs) vào việc ưu tiên các cặp ngôn ngữ sau:
Việt – Khmer và Khmer – Việt
Việt – Lào và Lào – Việt
Việt – Thái và Thái – Việt
Việt – Indo và Indo – Việt
Việt – Malay và Malay – Việt
Với ngôn ngữ tiếng Anh, hệ thống bảo đảm chất lượng gần tương đương Google Translate.
Do hệ thống được nhóm nghiên cứu tự phát triển, dựa trên hạ tầng kỹ thuật hỗ trợ lưu trữ dữ liệu ngôn ngữ lớn và năng lực siêu tính toán trí tuệ nhân tạo/học máy (AI/ML) mạnh nhất Việt Nam trên dòng chip tiên tiến trên thế giới Nvidia GPU A100 80GB, Viện Công nghệ thông tin hoàn toàn làm chủ các công nghệ liên quan và dễ dàng mở rộng ứng dụng sang các ngôn ngữ đích mới bao gồm các ngôn ngữ dân tộc thiểu số tại Việt Nam (thường là rất nghèo tài nguyên dữ liệu) như tiếng Mường, tiếng Thái… và các ngôn ngữ nước ngoài phổ biến như tiếng Trung, tiếng Pháp, tiếng Nga… khi cần.
Đặc biệt, hệ thống có khả năng tinh chỉnh để thích ứng với các miền ngôn ngữ chuyên sâu như y tế, luật… theo yêu cầu riêng của đối tác.






